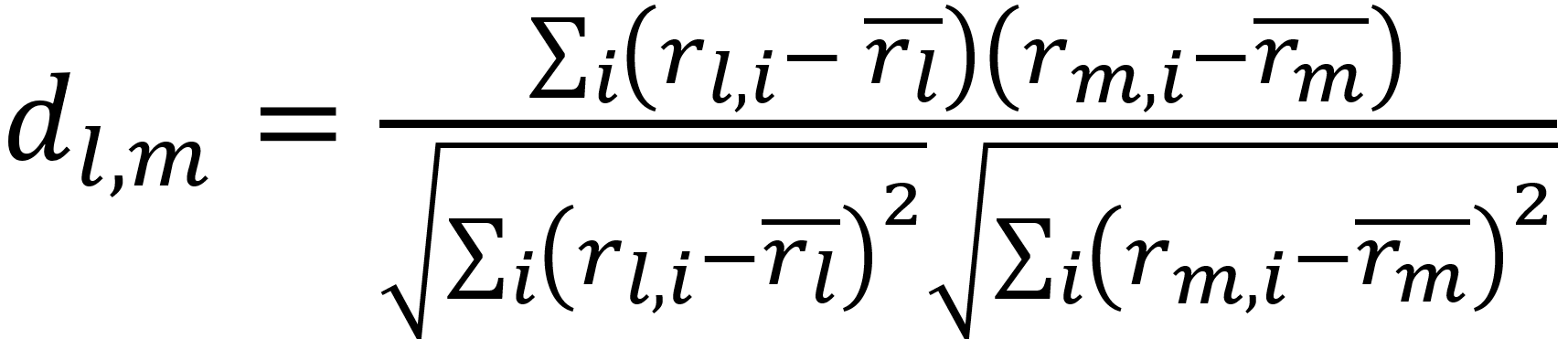
Earlier implementations of CF systems use the rating data to calculate the similarity between users or items and then make predictions or recommendations based on those similarities
There are two different types of memory-based CF algorithms, namely User Based and Item Based, which both use part or all of available user-item data to make predictions.
Pearson Correlation is one of the most common methods of calculating a similarity value between users.
For example, the Pearson correlation dl,m between learners l and m measures how two variables (learners) linearly relate with each other and it's represented by a scale of -1 to +1 (zero indicates no correlation).
The user-based Pearson Correlation similarity equation is as follows:
|
|
Where the items i have been rated by learners l and m, and r̄l is the average rating of the co-rated items of the lth learner. |
|---|
The details of the best neighbors learner-based algorithm are illustrated through the provided link:
Learn more about this algorithm.
The memory model is also associated with a number of
challenges.